
最近在玩什么?
简单介绍一下comfyui是什么?
花了大概一两个星期时间会基本的使用了,今年三月份的时候玩了一下webui,那时候还觉得生成图片还不怎么样,没想到现在已经进化到还行的阶段了,comfyui和webui都是使用Stable Diffusion模型来实现生图功能的前端交互界面,其中comfyui节点式的布局自由度比webui高,但没有webui那么容易上手。使用下来就是感觉还需要改进,比如生成的图手指变形的问题,偶而出现脸崩,需要配合其他节点来修复,不仅耗时效果也不一定能找到最好的。而生成视频(重绘)电脑就会变成取暖机,嘎嘎响,出来的图片就算同一批次也会出现衣服颜色不一致的情况,就不用说手和脸了,总之就是生成视频的还不成熟。
使用comfyui生成图片和视频
comfyui有着各种不一样的工作流用来实现各种需求,而生成图片的工作也有很多,最简单的就是文生图,然后图生图,图重绘,局部重绘,线稿上色,换背景等。而我比较喜欢文生图抽卡,输入各种提示词来让模型生成图片,比如这样的




巨物恐惧症了有木有?
还有机甲少女🤪(多图预警!!!)






二刺螈国风龙女(死肥宅最爱!)





美女(没人不爱看吧?)



可以看到手指变形问题,但是不影响dog.jpg
上面这些图片全是AI生成的,两三条腿的就不拿出来了/(ㄒoㄒ)/~~怎么样?有没有感觉很棒!再来看看做视频是什么效果?
花了一个星期摸索,修手修脸之类的,脸全修过所以一直闪,也不会剪辑就这样了(摆了)
然后半个月前又有了svd模型出来了,能通过一张图片生成视频,最近玩了一下,下面效果,看到obaby姐用这个存视频,我也来整一个,感觉比b站清楚耶,阿b好好反省
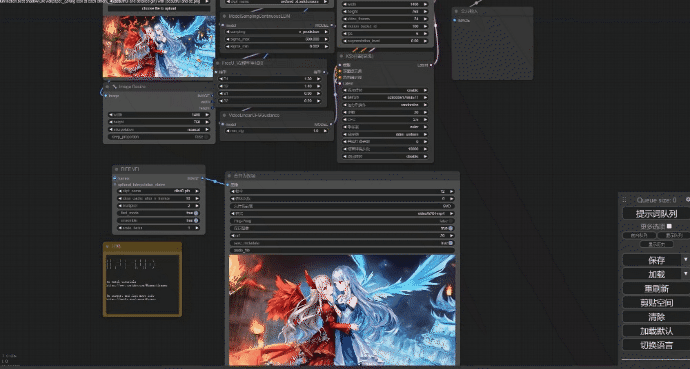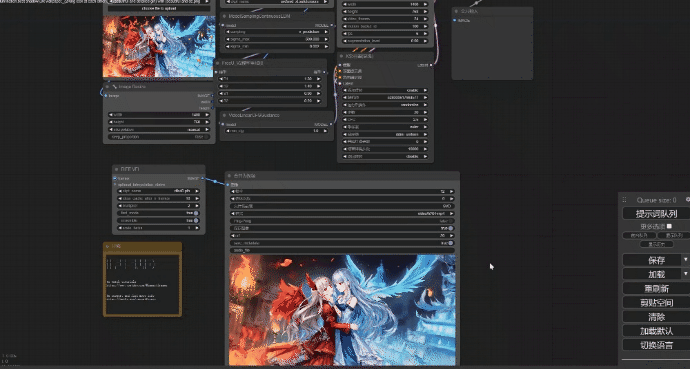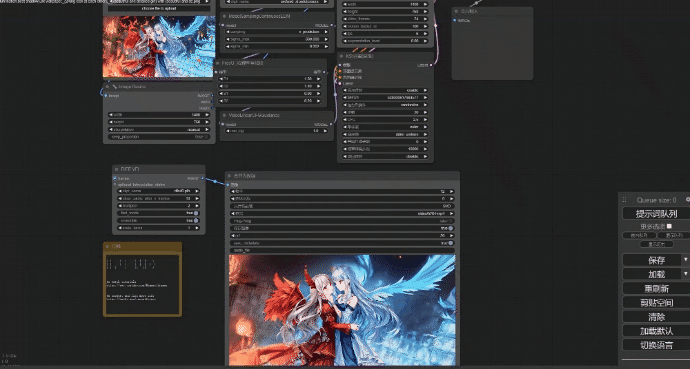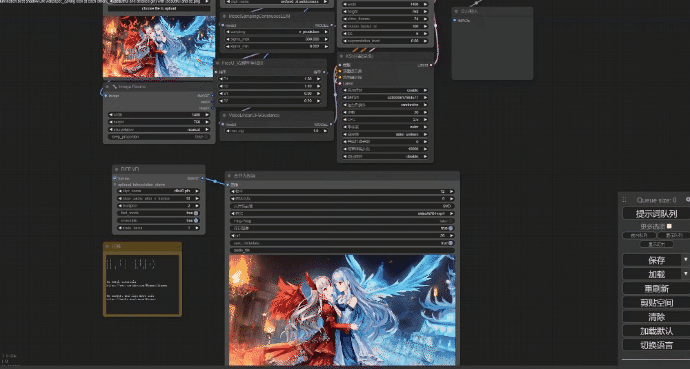
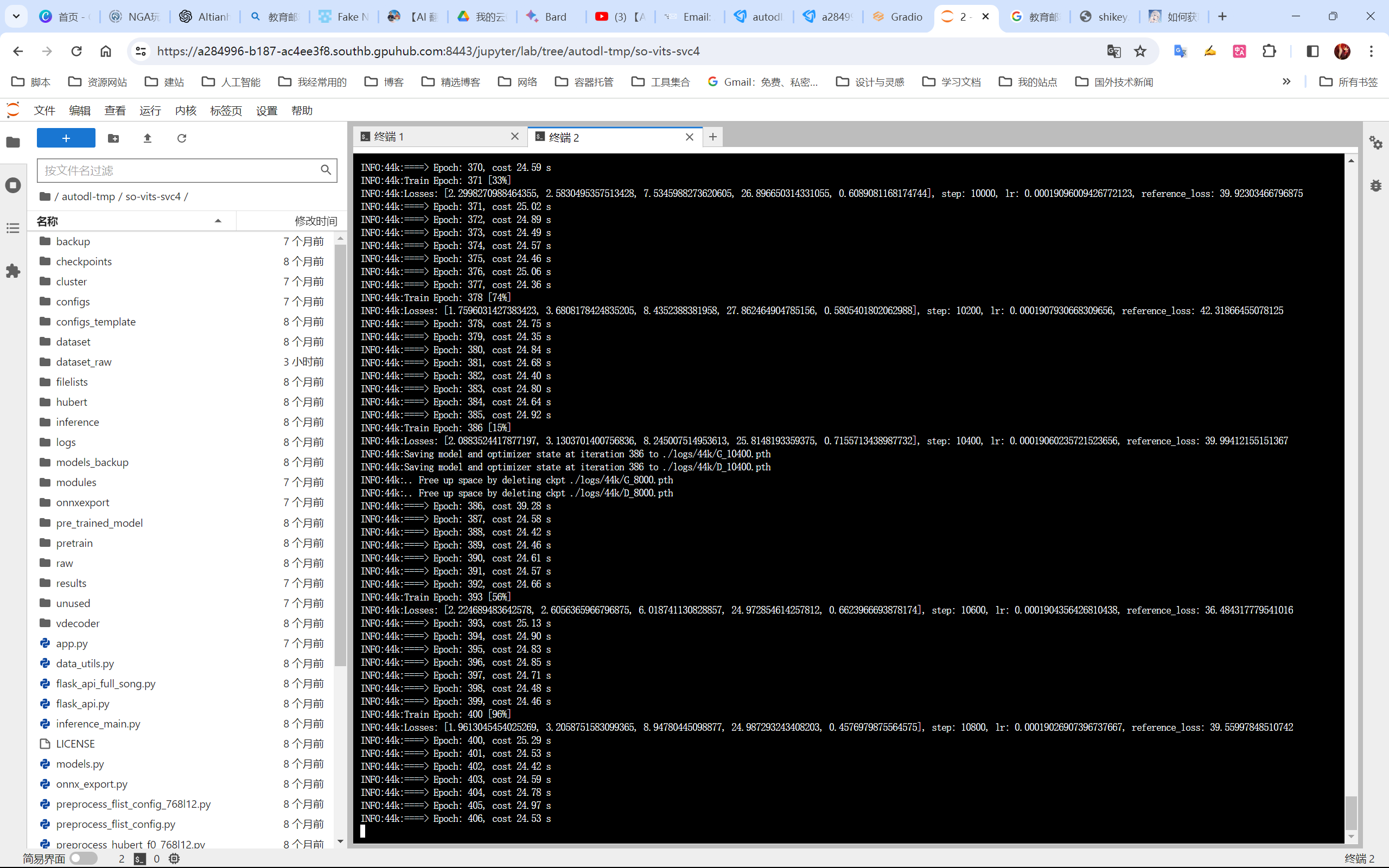
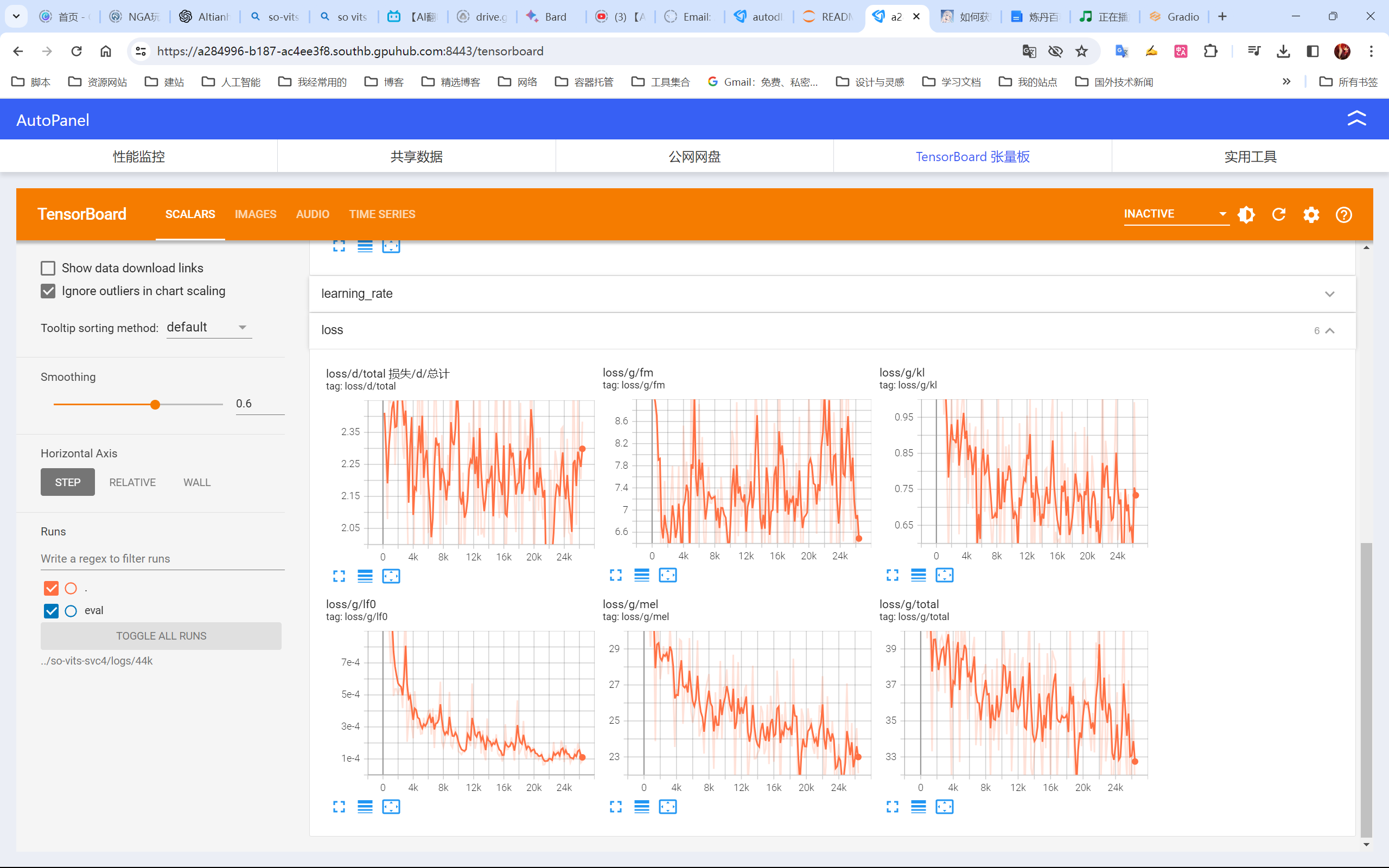
语言模型so-vits
喜欢的歌手是本兮,可惜在我中学的时候离开了人间,再也听不到她唱的歌了,所以我用so-vits练了她的声音。
当听到翻唱的粤语歌的时候我觉得本兮又活了过来!悲~
用来训练的音源我处理的不太干净,所以练出来的也不是太好,尝试声调太高太低或者是古风歌都很容易跑调,后面应该听都听不出来是AI的声音来。
开始练本兮lora模型
第一次用kaggle练,每周有30个小时的GPU算力,嘎嘎嘎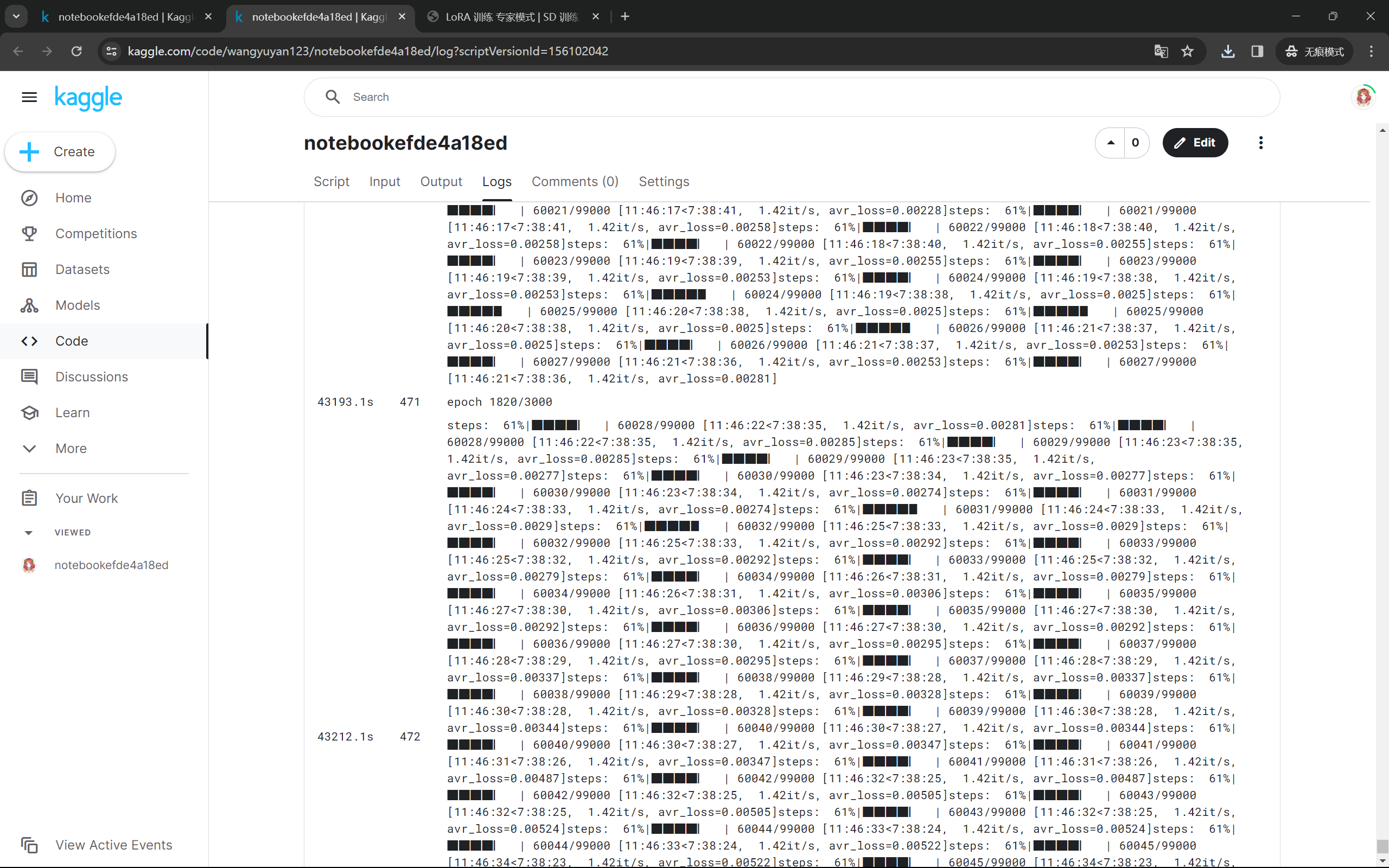
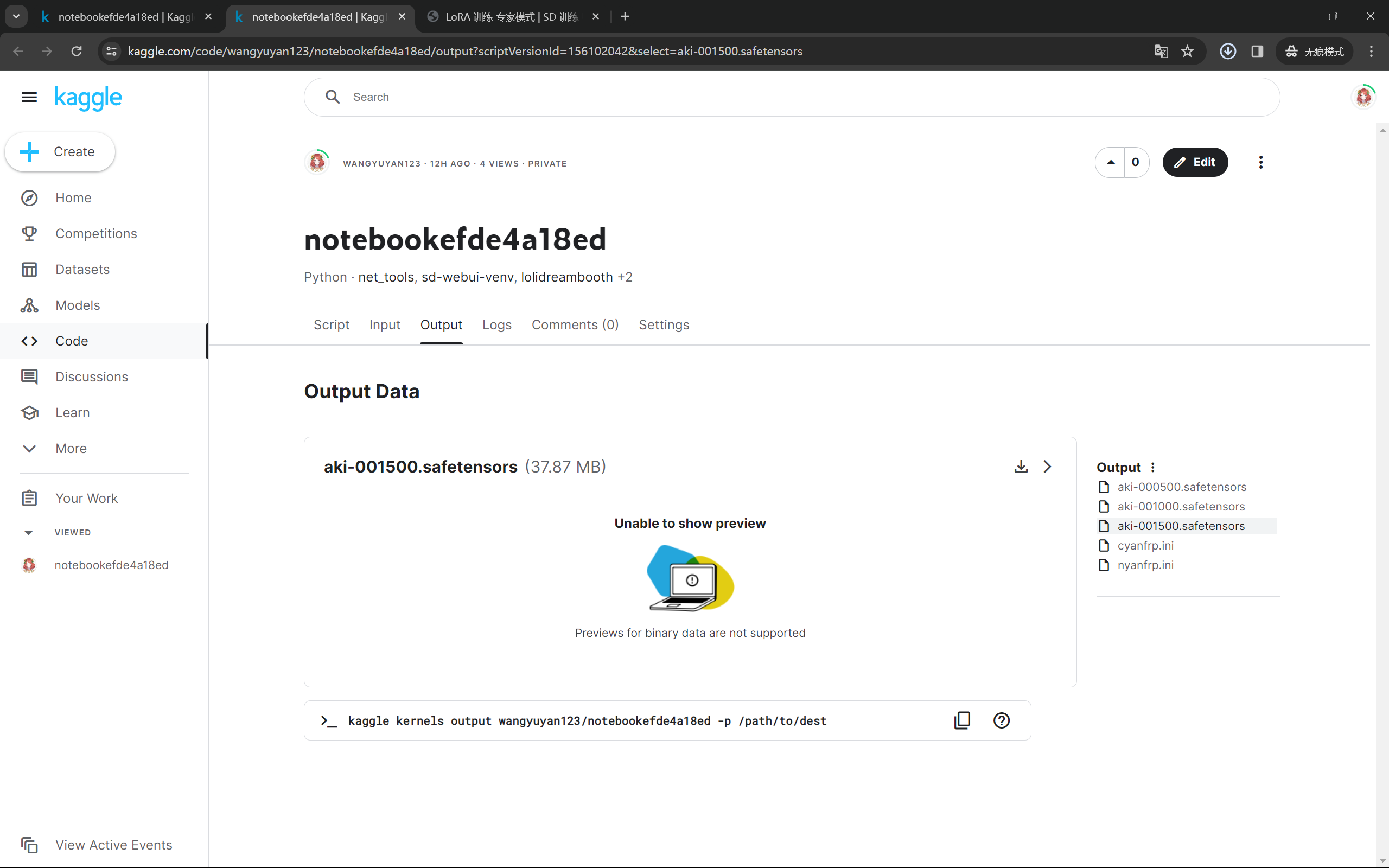
希望能出图吧!至此,也算记录了一下我最近在干的事,害,纯在瞎折腾。一年就要过去了我好像什么也没有改变,看各种大佬凡尔赛,很多时候都是想得太多做的又太少。可我真的有在花时间去学习,有时候感到焦虑就总是觉得时间不够用,甚至吃饭都觉得是浪费时间。可有时候又摆烂到可以玩一天游戏,甚至不知道这样做有什么意义?我走在正确的路上了吗?



